실행계획 기반 쿼리 튜닝으로 워크스페이스 문서 조회 22s → 300ms
핵심 결과 (TL;DR)
- Latency: 22초 → 300ms
- slow query 상위 구간(꼬리) 제거 → 피크 시간대 체감 지연 감소
- 실행계획(Explain)에서 Driving table 필터가 먼저 적용되도록 쿼리 구조를 재작성
- 데이터 분포 상 heavy hitter(특정 유저/조직이 대부분의 문서를 보유) 패턴을 확인했고, 장기적으로 **1년 이상 지난 문서 파티셔닝(또는 아카이빙)**을 제안
문제 상황
워크스페이스 “문서 목록/검색” API가 피크 시간대에 반복적으로 22초까지 지연되는 문제가 있었습니다. 평균(latency mean)보다 더 중요한 건 운영 체감이 큰 p95/p99 지연 상한이었고, 특정 조건 조합에서만 터지는 “꼬리 지연”이 서비스 경험을 망가뜨렸습니다.
관찰된 현상은 아래와 같았습니다.
- 문서 목록/검색 요청이 몰리는 시간대에 지연이 급격히 증가
- 특정 직원/조직에서만 유독 느림 (테넌트/조건 조합에 따라 편차 큼)
- 실행계획상 불필요한 스캔이 발생 → 인덱스를 타더라도 “너무 많이” 읽는 형태
접근 방법
핵심은 “감”이 아니라 느린 쿼리 로그 + 실행계획으로 병목을 분해하는 것이었습니다.
-
slow query에서 문제 쿼리(SELECT/COUNT) 후보를 추출
-
각 쿼리에 대해
EXPLAIN/EXPLAIN ANALYZE로- 어떤 테이블이 Driving table이 되는지
- Driving 테이블의 핵심 필터링 요소(
USER_ID,ORGANIZATION_ID)가 얼마나 빨리 적용되는지 - 예상 rows/filtered, extra(Using filesort 등) 확인
-
“드라이빙을 제대로 못 잡는” 케이스가 **특정 유저/조직(heavy hitter)**에 집중되어 있음을 데이터로 확인
-
쿼리를 Driving table의 선택성과 실행 순서가 보장되도록 재작성 + 인덱스 재정의
-
배포 전/후 동일 시나리오로 p95/p99 재측정
구현: 핵심은 “Driving table 필터를 먼저” 먹이는 구조
1) 왜 느렸나: Driving table에서 USER_ID/ORGANIZATION_ID 필터가 먼저 적용되지 않음
실행계획을 보면 SELECT/COUNT 모두에서 공통적으로,
- Driving table이 충분히 좁혀지기 전에
- 조인/정렬/추가 조건이 먼저 개입하면서
- 결과적으로 스캔 범위가 커지는 패턴이 반복됐습니다.
즉, “문서 조회”의 본질은 결국 draft(문서) 같은 큰 테이블에서
USER_ID, ORGANIZATION_ID로 먼저 확 줄이고(high selectivity),
그 다음에 필요한 조인/정렬을 해야 하는데,
그 순서가 깨지면서 heavy hitter 구간에서 병목이 폭발한 겁니다.
포인트는 두 가지입니다.
- 드라이빙 테이블의 필터링 요소(
organization_id/user_id)로 먼저 범위를 줄임
COUNT 쿼리도 같은 철학입니다. “조인해서 카운트”가 아니라, 카운트에 꼭 필요한 조건만 남기고 Driving table을 가장 먼저 줄이는 형태로 정리했습니다.
2) 인덱스 재설계: “= 조건 → range → 정렬/커버링” 순서
쿼리 구조를 바꿔도 인덱스가 받쳐주지 않으면 효과가 제한적입니다.
이번 케이스는 USER_ID, ORGANIZATION_ID가 핵심 필터였기 때문에 다음 원칙으로 인덱스를 재정의했습니다.
- 동등 조건(equality) 컬럼을 앞에:
organization_id,user_id - 그 다음 range:
created_at같은 기간 조건 - 그 다음 정렬/커버링에 필요한 컬럼:
updated_at등
예시:
-- 예시: 문서 목록/검색에서 가장 자주 쓰는 필터/정렬에 맞춘 인덱스
-- 1. 내가 속한 조직의 문서 조회
CREATE INDEX idx_draft_org_user_created_updated
ON draft (organization_id, created_at, updated_at);
-- 2. 내 문서 조회
CREATE INDEX idx_draft_org_user_created_updated
ON draft (user_id, created_at, updated_at);
heavy hitter 분석과 파티셔닝(또는 아카이빙) 제안
튜닝 과정에서 중요한 발견은 이거였습니다.
대부분의 직원/조직은 300ms로 잘 나오는데, 특정 직원/조직이 전체 문서의 대부분을 보유한 경우가 존재했고, 그 구간에서 병목이 터진다.
실제로 아래 같은 분포 분석으로 heavy hitter가 눈에 띄었습니다.
SELECT COUNT(1), user_id
FROM draft
GROUP BY user_id
ORDER BY COUNT(1) DESC;
SELECT COUNT(1), organization_id
FROM draft
GROUP BY organization_id
ORDER BY COUNT(1) DESC;
첨부된 그래프도 “대부분은 낮은데 특정 구간에서만 COUNT가 급증”하는 형태로, 전형적인 heavy hitter 분포를 보여줍니다. 이런 분포에서는 쿼리 튜닝만으로 꼬리 지연을 0으로 만들기 어렵고, 데이터 수명을 이용한 물리적 전략이 필요해집니다.
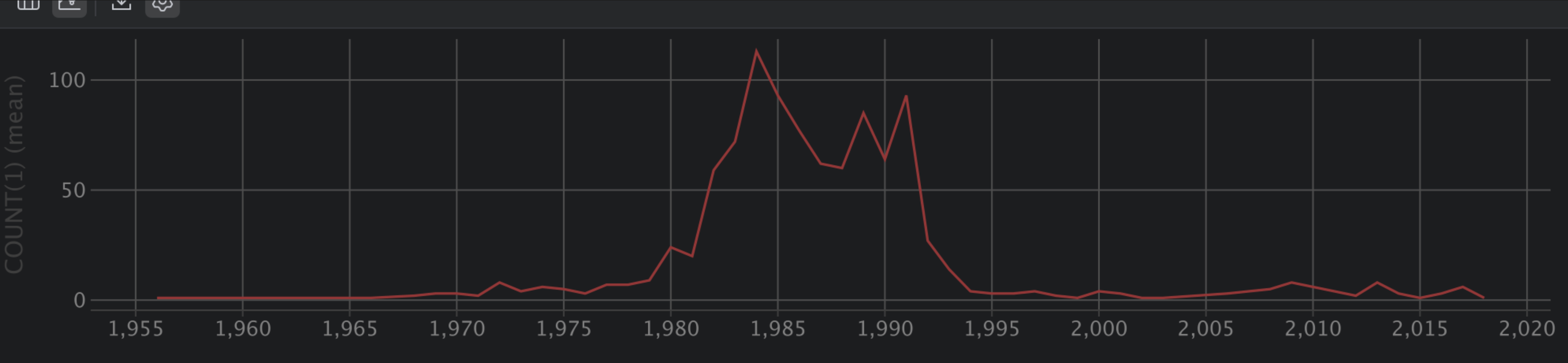
그래서 운영 제안으로:
-
1년 이상 지난 문서는 조회 빈도가 상대적으로 낮고,
-
전체 데이터량/인덱스 크기/캐시 효율에 큰 영향을 주므로,
-
created_at기준 파티셔닝(또는 cold storage 아카이빙)으로- “최근 1년” 핫 데이터 쿼리의 스캔/인덱스 효율을 안정화하자
검증
배포 전/후 동일 조건으로 아래를 확인했습니다.
- 피크 시간대 p95/p99 추이가 안정화되는지
- slow query 상위 구간이 제거되는지
- 사용자 체감(문서 목록 진입/검색 결과 노출)이 개선되는지
결과적으로
- 22s → 300ms
- 피크 시점의 지연 편차(꼬리)가 크게 줄었고,
- 문제가 되던 특정 직원/조직 케이스도 “운영 가능한 수준”(1.5s)으로 내려왔습니다.
회고
- 캐시를 붙이기 전에, 실행계획 기반으로 “왜 많이 읽는지”를 먼저 제거하는 게 가장 효과가 컸습니다.
- 데이터 분포가 heavy hitter이면 튜닝은 상한선이 있습니다. 결국 **파티셔닝/아카이빙(데이터 수명 전략)**을 병행해야 p99가 더 안정적으로 내려갑니다.
- 성능개선의 목표는 “평균”이 아니라, 사용자 경험을 망치는 꼬리(p95/p99) 제거라는 걸 다시 확인했습니다.
Diagram Note: 병목 진단 및 개선 흐름(요약)
diagram rendering...